
Android 8.0 包含用于测试吞吐量和延迟的 binder 和 hwbinder 性能测试。虽然存在许多可检测到明显性能问题的场景,但运行此类场景可能非常耗时,并且通常在系统集成后才能获得结果。使用提供的性能测试可以更轻松地在开发期间进行测试、更早地检测到严重问题并改善用户体验。
性能测试包括以下四个类别
- binder 吞吐量(在
system/libhwbinder/vts/performance/Benchmark_binder.cpp中提供) - binder 延迟(在
frameworks/native/libs/binder/tests/schd-dbg.cpp中提供) - hwbinder 吞吐量(在
system/libhwbinder/vts/performance/Benchmark.cpp中提供) - hwbinder 延迟(在
system/libhwbinder/vts/performance/Latency.cpp中提供)
关于 binder 和 hwbinder
Binder 和 hwbinder 是 Android 进程间通信 (IPC) 基础架构,它们共享相同的 Linux 驱动程序,但在质量方面存在以下差异
| 方面 | binder | hwbinder |
|---|---|---|
| 用途 | 为框架提供通用 IPC 方案 | 与硬件通信 |
| 属性 | 针对 Android 框架使用情况进行了优化 | 最低开销低延迟 |
| 更改前台/后台的调度政策 | 是 | 否 |
| 参数传递 | 使用 Parcel 对象支持的序列化 | 使用分散缓冲区,避免了 Parcel 序列化所需的数据复制开销 |
| 优先级继承 | 否 | 是 |
Binder 和 hwbinder 进程
systrace 可视化工具会按如下方式显示事务
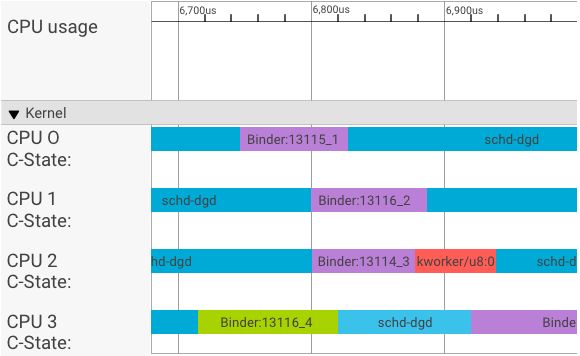
在以上示例中
- 四个 (4) schd-dbg 进程是客户端进程。
- 四个 (4) binder 进程是服务器进程(名称以 Binder 开头,以序列号结尾)。
- 客户端进程始终与服务器进程配对,服务器进程专用于其客户端。
- 所有客户端-服务器进程对都由内核并发独立调度。
在 CPU 1 中,操作系统内核执行客户端以发出请求。然后,它会尽可能使用同一 CPU 唤醒服务器进程、处理请求,并在请求完成后上下文切换回来。
吞吐量与延迟
在客户端和服务器进程无缝切换的理想事务中,吞吐量和延迟测试不会产生明显不同的消息。但是,当操作系统内核正在处理来自硬件的中断请求 (IRQ)、等待锁或只是选择不立即处理消息时,可能会形成延迟气泡。
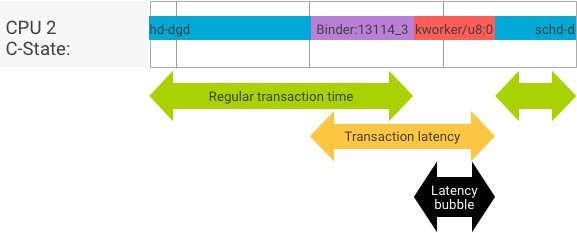
吞吐量测试生成大量具有不同有效负载大小的事务,从而为常规事务时间(在最佳情况下)和 binder 可以实现的最大吞吐量提供良好的估计。
相比之下,延迟测试不对有效负载执行任何操作,以最大限度地减少常规事务时间。我们可以使用事务时间来估计 binder 开销,统计最坏情况,并计算延迟满足指定期限的事务的比率。
处理优先级反转
当优先级较高的线程在逻辑上等待优先级较低的线程时,会发生优先级反转。实时 (RT) 应用存在优先级反转问题
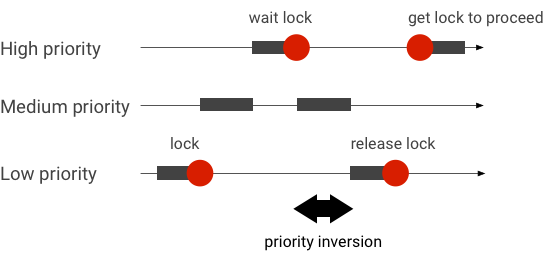
使用 Linux Completely Fair Scheduler (CFS) 调度时,即使其他线程具有更高的优先级,线程也始终有机会运行。 因此,使用 CFS 调度的应用程序可以按预期行为处理优先级反转,而不是将其视为问题。 但是,如果 Android 框架需要 RT 调度来保证高优先级线程的特权,则必须解决优先级反转问题。
Binder 事务期间的优先级反转示例(当等待 binder 线程服务时,RT 线程在逻辑上被其他 CFS 线程阻塞)

为了避免阻塞,您可以使用优先级继承,在 Binder 线程为来自 RT 客户端的请求提供服务时,临时将 Binder 线程提升为 RT 线程。 请记住,RT 调度资源有限,应谨慎使用。 在具有 n 个 CPU 的系统中,当前 RT 线程的最大数量也为 n; 如果所有 CPU 都被其他 RT 线程占用,则额外的 RT 线程可能需要等待(并因此错过其截止时间)。
为了解决所有可能的优先级反转,您可以对 binder 和 hwbinder 都使用优先级继承。 但是,由于 binder 在系统中被广泛使用,为 binder 事务启用优先级继承可能会使系统充斥着超出其服务能力的 RT 线程。
运行吞吐量测试
吞吐量测试是针对 binder/hwbinder 事务吞吐量运行的。 在未过载的系统中,延迟抖动很少见,只要迭代次数足够高,它们的影响就可以消除。
- binder 吞吐量测试位于
system/libhwbinder/vts/performance/Benchmark_binder.cpp中。 - hwbinder 吞吐量测试位于
system/libhwbinder/vts/performance/Benchmark.cpp中。
测试结果
使用不同有效负载大小的事务的吞吐量测试结果示例
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- 时间 表示以实际时间测量的往返延迟。
- CPU 表示 CPU 为测试调度的累积时间。
- 迭代次数 表示测试函数执行的次数。
例如,对于 8 字节有效负载
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… binder 可以实现的最大吞吐量计算如下
8 字节有效负载的最大吞吐量 = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
测试选项
要以 .json 格式获取结果,请使用 --benchmark_format=json 参数运行测试
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}运行延迟测试
延迟测试测量客户端开始初始化事务、切换到服务器进程进行处理并接收结果所花费的时间。 该测试还查找可能对事务延迟产生负面影响的已知不良调度器行为,例如不支持优先级继承或不遵守同步标志的调度器。
- binder 延迟测试位于
frameworks/native/libs/binder/tests/schd-dbg.cpp中。 - hwbinder 延迟测试位于
system/libhwbinder/vts/performance/Latency.cpp中。
测试结果
结果(以 .json 格式)显示平均/最佳/最差延迟以及错过截止时间的次数的统计信息。
测试选项
延迟测试采用以下选项
| 命令 | 描述 |
|---|---|
-i 值 |
指定迭代次数。 |
-pair 值 |
指定进程对的数量。 |
-deadline_us 2500 |
以 us 为单位指定截止时间。 |
-v |
获取详细(调试)输出。 |
-trace |
在命中截止时间时停止跟踪。 |
以下部分详细介绍每个选项,描述用法,并提供示例结果。
指定迭代次数
具有大量迭代次数且禁用详细输出的示例
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}这些测试结果显示以下内容
"pair":3- 创建一个客户端和服务器对。
"iterations": 5000- 包括 5000 次迭代。
"deadline_us":2500- 截止时间为 2500us(2.5ms); 大多数事务都应满足此值。
"I": 10000- 单次测试迭代包括两个 (2) 事务
- 一个由正常优先级 (
CFS other) 执行的事务 - 一个由实时优先级 (
RT-fifo) 执行的事务
- 一个由正常优先级 (
"S": 9352- 9352 个事务在同一 CPU 中同步。
"R": 0.9352- 表示客户端和服务器在同一 CPU 中同步的比率。
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- 由正常优先级调用者发出的所有事务的平均 (
avg)、最差 (wst) 和最佳 (bst) 情况。 两个事务miss错过截止时间,使满足率 (meetR) 为 0.9996。 "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- 与
other_ms类似,但适用于由具有rt_fifo优先级的客户端发出的事务。fifo_ms很可能(但不是必需的)比other_ms具有更好的结果,具有更低的avg和wst值以及更高的meetR(在后台负载的情况下,差异可能更加显着)。
注意: 后台负载可能会影响吞吐量结果和延迟测试中的 other_ms 元组。 只要后台负载的优先级低于 RT-fifo,只有 fifo_ms 可能会显示相似的结果。
指定对值
每个客户端进程都与一个专用于该客户端的服务器进程配对,并且每对都可以独立调度到任何 CPU。 但是,只要 SYNC 标志为 honor,CPU 迁移就不应在事务期间发生。
确保系统未过载! 虽然过载系统中的高延迟是预期的,但过载系统的测试结果无法提供有用的信息。 要测试具有更高压力的系统,请使用 -pair #cpu-1(或谨慎使用 -pair #cpu)。 使用 -pair n 且 n > #cpu 进行测试会使系统过载并生成无用的信息。
指定截止时间值
在广泛的用户场景测试(在合格产品上运行延迟测试)之后,我们确定 2.5 毫秒是需要满足的截止时间。 对于具有更高要求的新应用程序(例如每秒 1000 张照片),此截止时间值将会更改。
指定详细输出
使用 -v 选项显示详细输出。 示例
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- 该服务线程使用
SCHED_OTHER优先级创建,并在CPU:1中以pid 8674运行。 - 该第一个事务然后由
fifo-caller启动。 为了服务此事务,hwbinder 将服务器 (pid: 8674 tid: 8676) 的优先级升级为 99,并将其标记为瞬态调度类(打印为???)。 然后,调度器将服务器进程置于CPU:0中运行,并将其与其客户端同步到同一 CPU。 - 该第二个事务调用者具有
SCHED_OTHER优先级。 服务器降级自身并以SCHED_OTHER优先级为调用者提供服务。
使用跟踪进行调试
您可以指定 -trace 选项来调试延迟问题。 使用后,延迟测试会在检测到不良延迟的时刻停止 tracelog 记录。 示例
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
以下组件可能会影响延迟
- Android 构建模式。 Eng 模式通常比 userdebug 模式慢。
- 框架。 框架服务如何使用
ioctl来配置 binder? - Binder 驱动程序。 驱动程序是否支持细粒度锁定? 它是否包含所有性能调整补丁?
- 内核版本。 内核的实时能力越好,结果就越好。
- 内核配置。 内核配置是否包含
DEBUG配置,例如DEBUG_PREEMPT和DEBUG_SPIN_LOCK? - 内核调度器。 内核是否具有 Energy-Aware scheduler (EAS) 或 Heterogeneous Multi-Processing (HMP) 调度器? 任何内核驱动程序(
cpu-freq驱动程序、cpu-idle驱动程序、cpu-hotplug等)是否会影响调度器?