
systrace 是分析 Android 设备性能的主要工具。然而,它实际上是其他工具的包装器。它是设备端可执行文件 atrace 的主机端包装器,atrace 控制用户空间跟踪并设置 ftrace,而 ftrace 是 Linux 内核中的主要跟踪机制。systrace 使用 atrace 启用跟踪,然后读取 ftrace 缓冲区,并将其全部包装在一个独立的 HTML 查看器中。(虽然较新的内核支持 Linux 增强型 Berkeley 数据包过滤器 (eBPF),但以下文档适用于 3.18 内核(无 eFPF),因为 Pixel/Pixel XL 上使用的是该内核。)
systrace 由 Google Android 和 Google Chrome 团队拥有,并且作为 Catapult 项目 的一部分开源。除了 systrace 之外,Catapult 还包括其他有用的实用程序。例如,ftrace 具有比 systrace 或 atrace 直接启用的更多功能,并且包含一些对调试性能问题至关重要的高级功能。(这些功能需要 root 访问权限,通常还需要新的内核。)
运行 systrace
在 Pixel/Pixel XL 上调试抖动时,请从以下命令开始
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
当与 GPU 和显示流水线活动所需的其他跟踪点结合使用时,这使您能够从用户输入跟踪到屏幕上显示的帧。将缓冲区大小设置为较大值以避免丢失事件(因为如果没有大缓冲区,某些 CPU 在跟踪中的某些点之后可能不包含任何事件)。
在查看 systrace 时,请记住每个事件都由 CPU 上的某些操作触发。
由于 systrace 构建在 ftrace 之上,而 ftrace 在 CPU 上运行,因此 CPU 上的某些操作必须写入 ftrace 缓冲区,该缓冲区记录硬件更改。这意味着,如果您想知道为什么显示 fence 的状态发生了变化,您可以查看 CPU 在其转换的确切时间点正在运行什么(CPU 上运行的某些操作触发了日志中的更改)。这个概念是使用 systrace 分析性能的基础。
示例:正常工作的帧
此示例描述了正常 UI 流水线的 systrace。要跟随示例进行操作,请下载 zip 文件(其中还包括本节中提到的其他跟踪),解压缩文件,然后在浏览器中打开 systrace_tutorial.html 文件。请注意,此 systrace 是一个大文件;除非您在日常工作中使用 systrace,否则这很可能是一个比您以前在单个跟踪中看到的包含更多信息的跟踪。
对于一致的周期性工作负载(例如 TouchLatency),UI 流水线包含以下内容
- SurfaceFlinger 中的 EventThread 唤醒应用 UI 线程,发出信号表示是时候渲染新帧了。
- 应用在 UI 线程、RenderThread 和 hwuiTasks 中渲染帧,使用 CPU 和 GPU 资源。这是 UI 消耗的大部分容量。
- 应用使用 binder 将渲染的帧发送到 SurfaceFlinger,然后 SurfaceFlinger 进入睡眠状态。
- SurfaceFlinger 中的第二个 EventThread 唤醒 SurfaceFlinger 以触发合成和显示输出。如果 SurfaceFlinger 确定没有工作要做,它将返回睡眠状态。
- SurfaceFlinger 使用硬件合成器 (HWC)/硬件合成器 2 (HWC2) 或 GL 处理合成。HWC/HWC2 合成速度更快、功耗更低,但根据片上系统 (SoC) 的不同,存在局限性。这通常需要约 4-6 毫秒,但可以与步骤 2 重叠,因为 Android 应用始终是三重缓冲的。(虽然应用始终是三重缓冲的,但 SurfaceFlinger 中可能只有一个待处理帧在等待,这使其看起来与双重缓冲相同。)
- SurfaceFlinger 使用供应商驱动程序将最终输出分派到显示屏,然后返回睡眠状态,等待 EventThread 唤醒。
让我们逐步了解从 15409 毫秒开始的帧
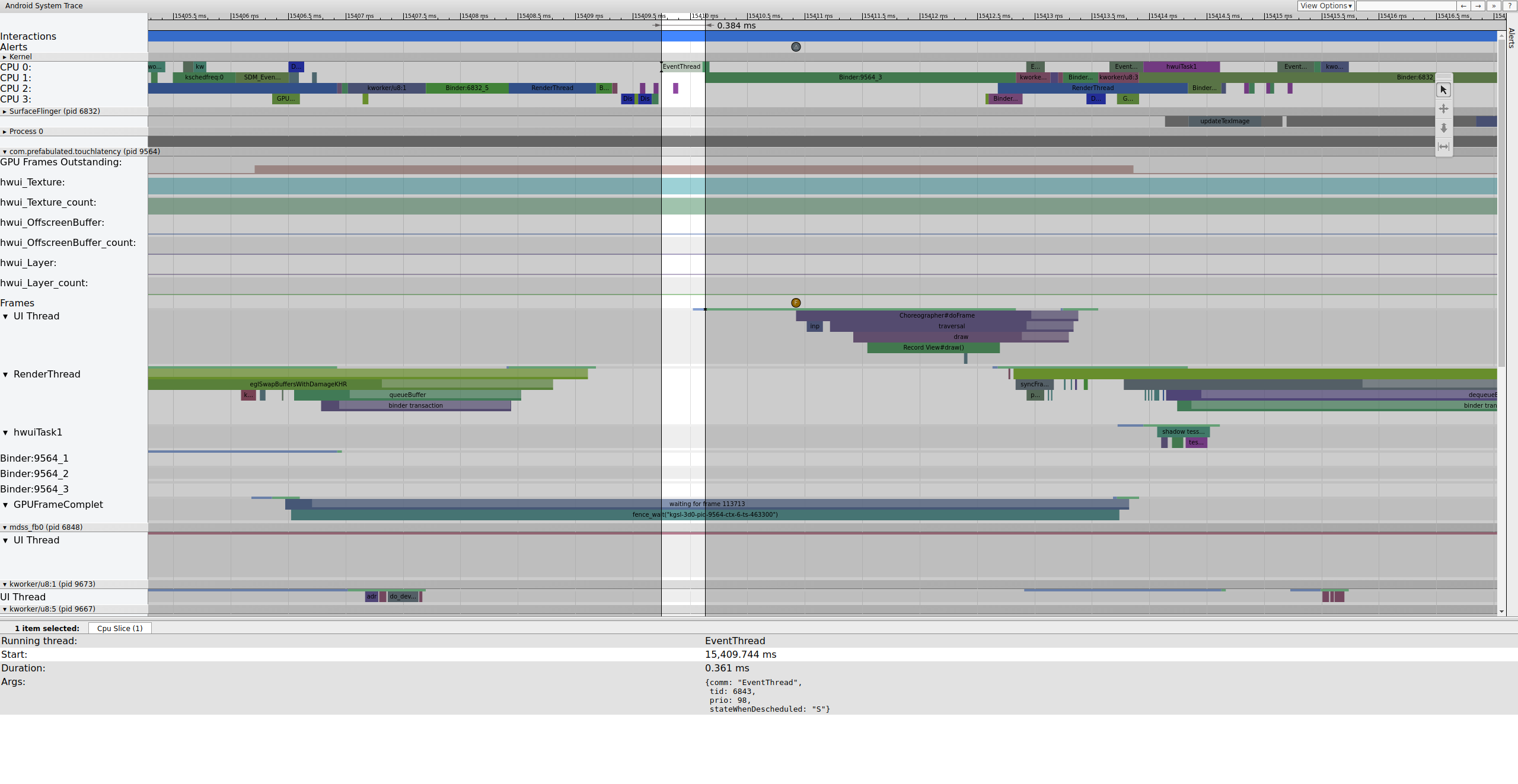
图 1 是一个被正常帧包围的正常帧,因此它是理解 UI 流水线如何工作的一个很好的起点。TouchLatency 的 UI 线程行在不同时间包含不同的颜色。条形表示线程的不同状态
- 灰色。睡眠。
- 蓝色。 可运行(它可以运行,但调度程序尚未选择它运行)。
- 绿色。 正在积极运行(调度程序认为它正在运行)。
- 红色。 不可中断睡眠(通常在内核中的锁上睡眠)。可能指示 I/O 负载。对于调试性能问题非常有用。
- 橙色。 由于 I/O 负载导致的不可中断睡眠。
要查看不可中断睡眠的原因(可从 sched_blocked_reason 跟踪点获得),请选择红色不可中断睡眠切片。
当 EventThread 正在运行时,TouchLatency 的 UI 线程变为可运行状态。要查看是什么唤醒了它,请单击蓝色部分。
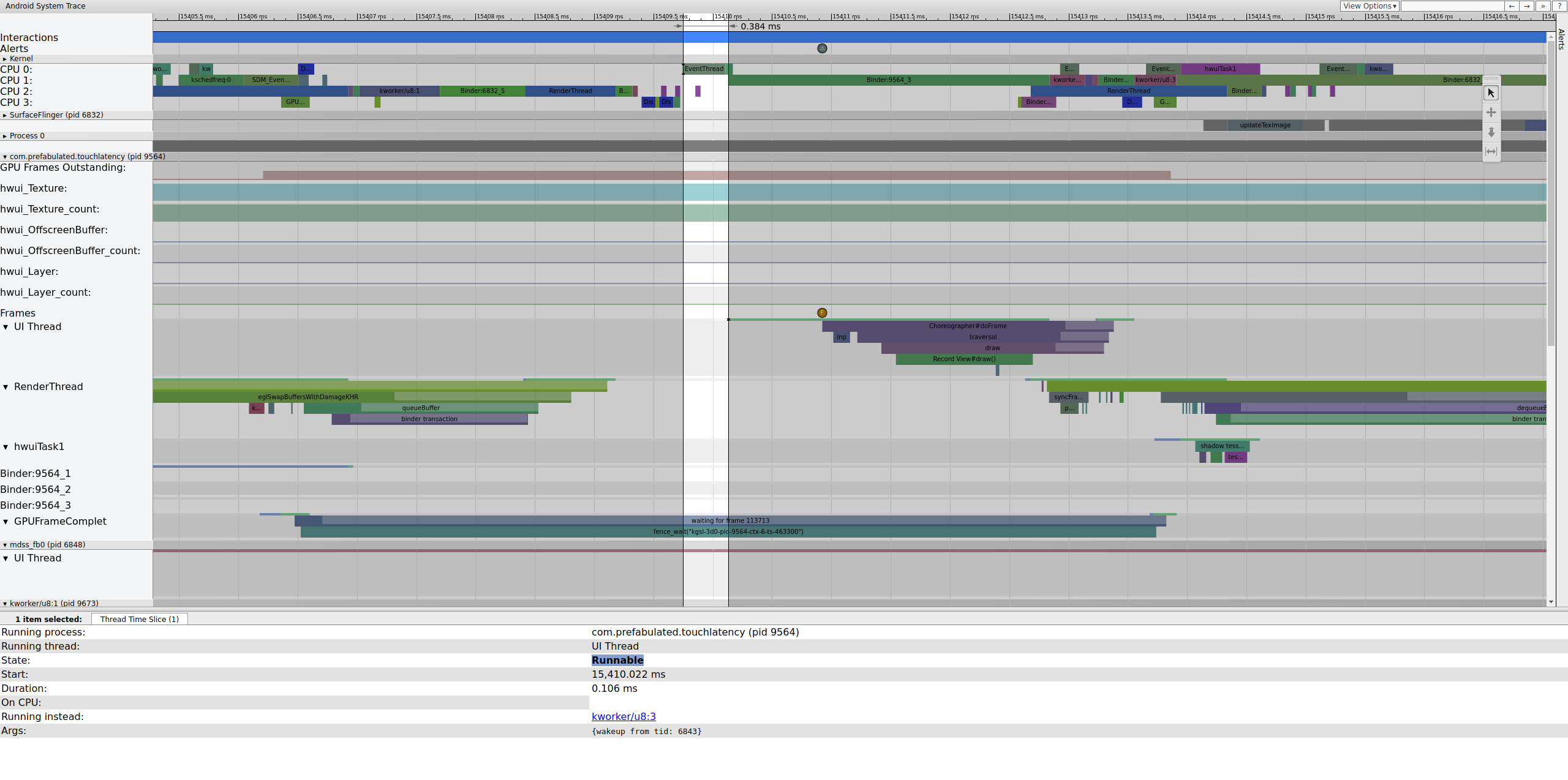
图 2 显示 TouchLatency UI 线程由 tid 6843 唤醒,该 tid 对应于 EventThread。UI 线程唤醒,渲染帧,并将其排队以供 SurfaceFlinger 使用。
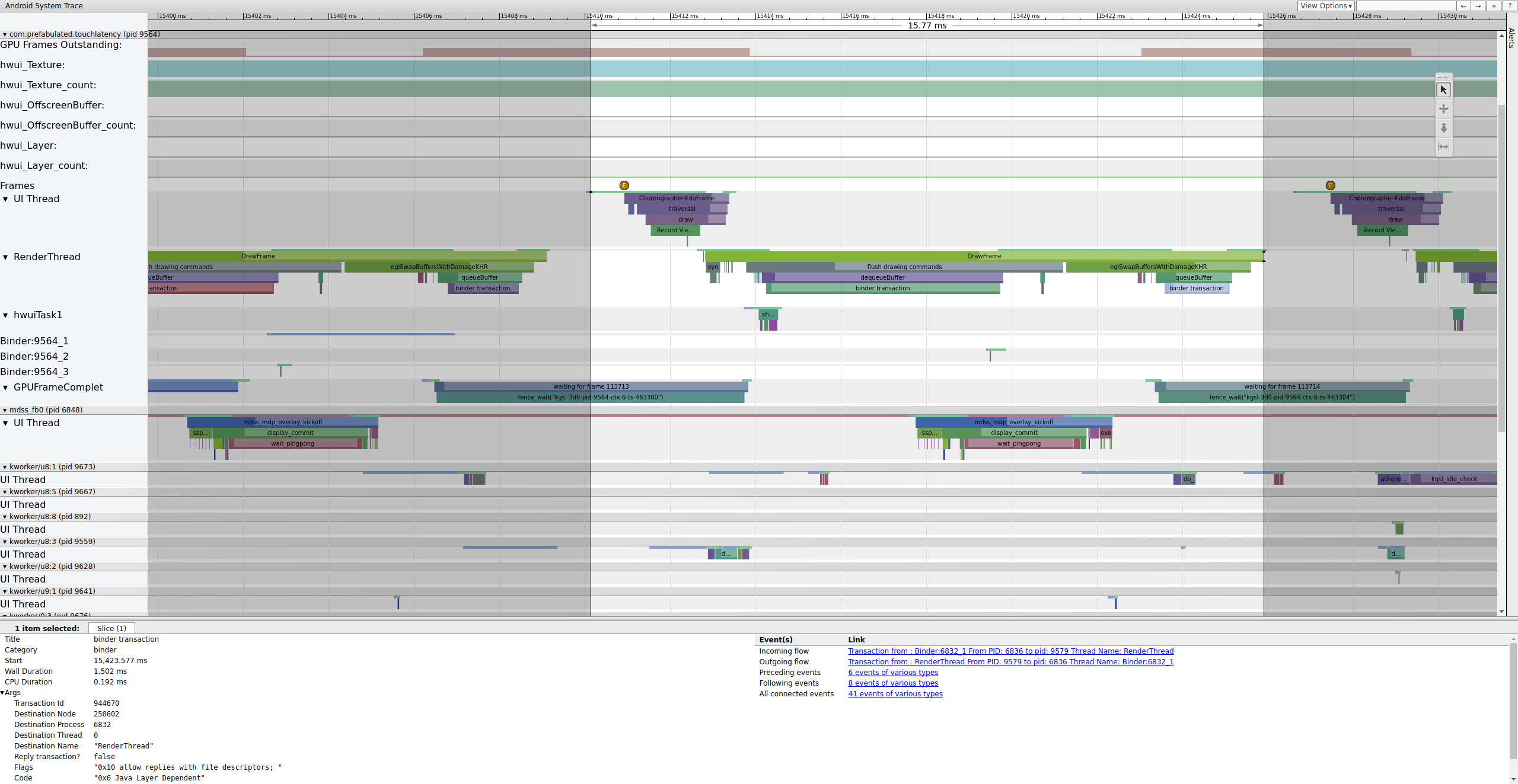
如果在跟踪中启用了 binder_driver 标记,您可以选择一个 binder 事务以查看有关该事务中涉及的所有进程的信息。
图 4 显示,在 15,423.65 毫秒时,SurfaceFlinger 中的 Binder:6832_1 由于 tid 9579(即 TouchLatency 的 RenderThread)而变为可运行状态。您还可以看到 binder 事务两侧的 queueBuffer。
在 SurfaceFlinger 端的 queueBuffer 期间,来自 TouchLatency 的待处理帧数从 1 变为 2。
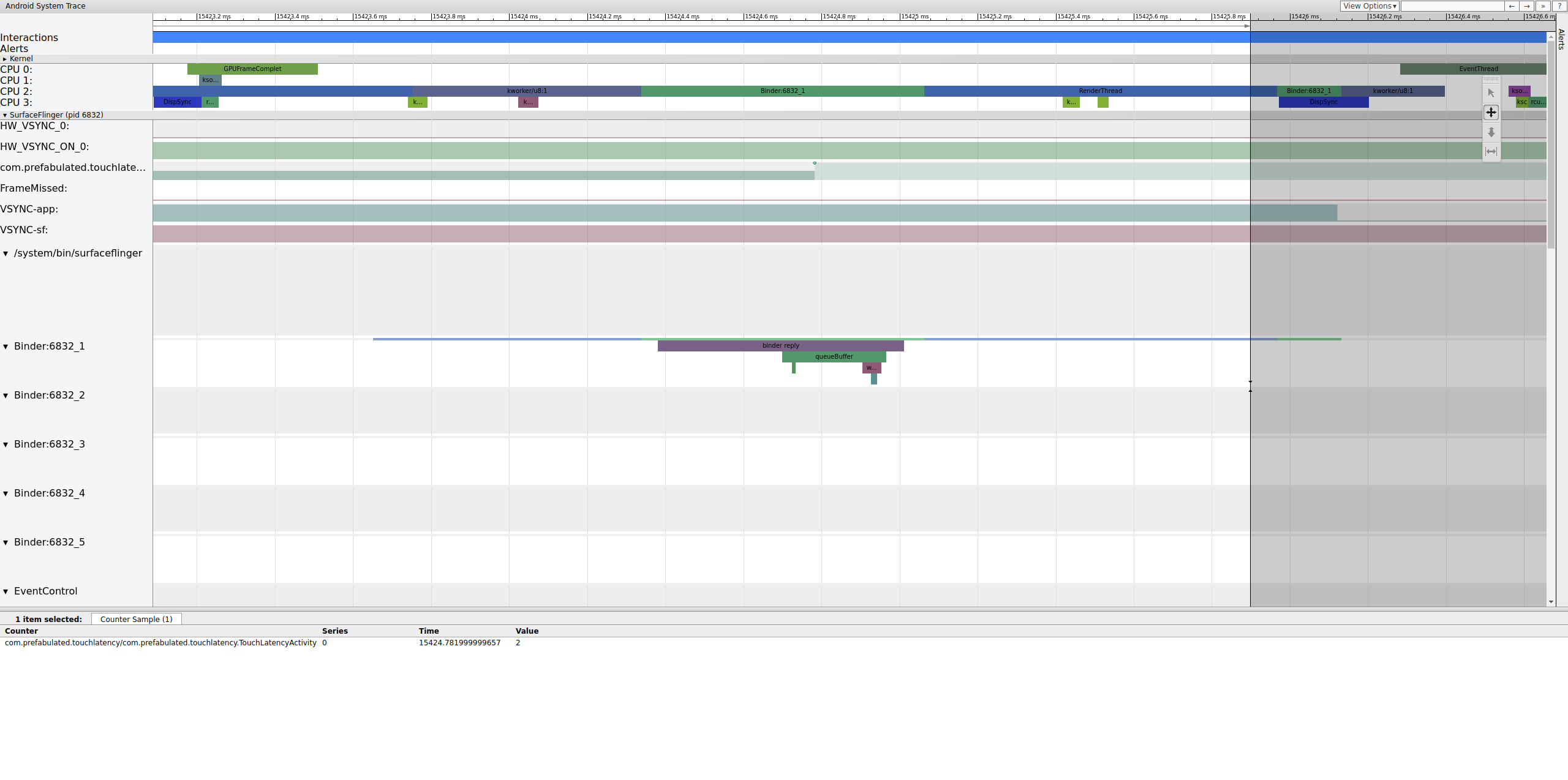
图 5 显示了三重缓冲,其中有两个已完成的帧,并且应用即将开始渲染第三个帧。这是因为我们已经丢弃了一些帧,因此应用保留了两个待处理帧而不是一个,以尽量避免进一步丢帧。
此后不久,SurfaceFlinger 的主线程被第二个 EventThread 唤醒,以便它可以将较旧的待处理帧输出到显示屏
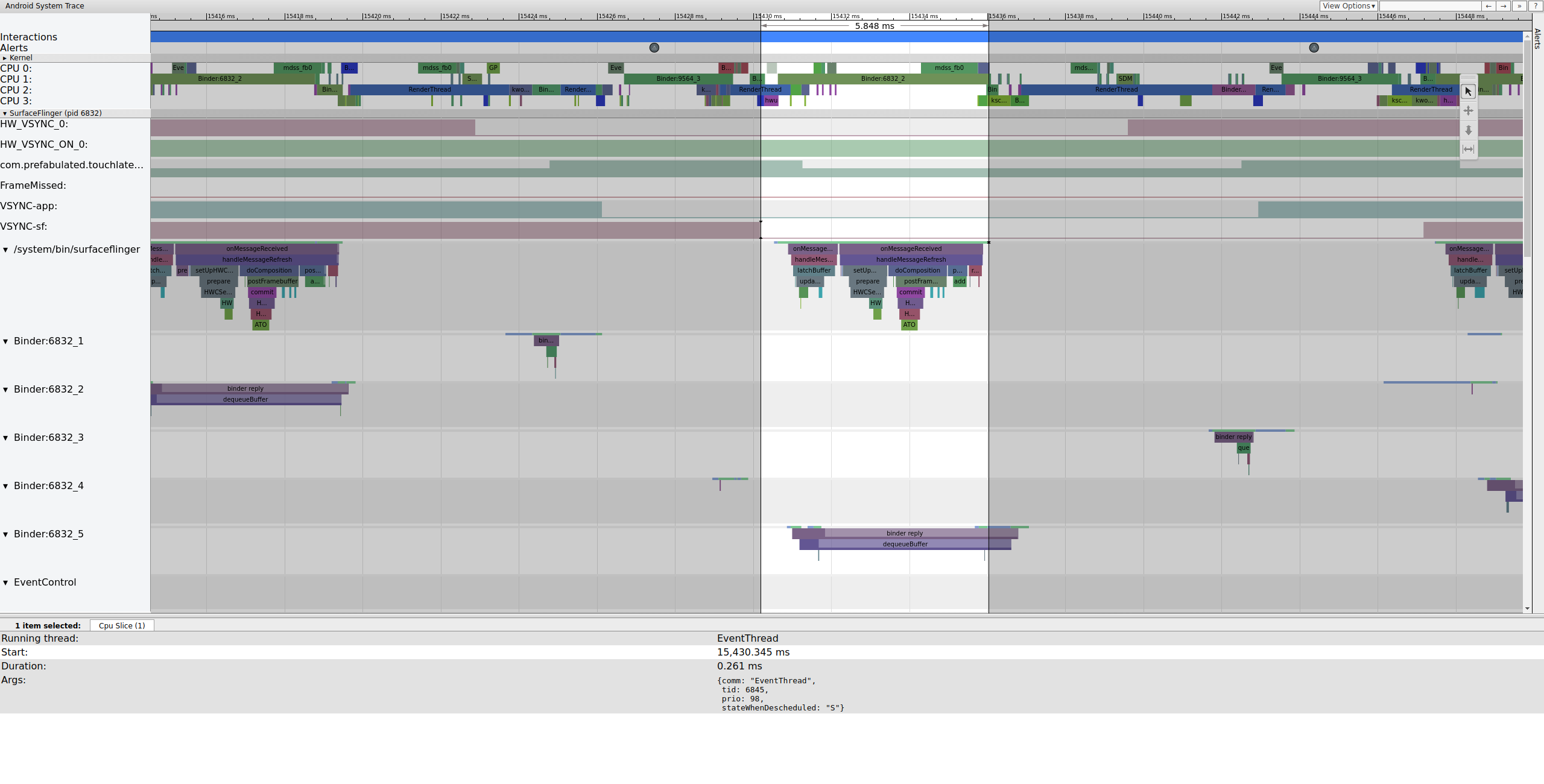
SurfaceFlinger 首先锁定较旧的待处理缓冲区,这导致待处理缓冲区计数从 2 减少到 1。
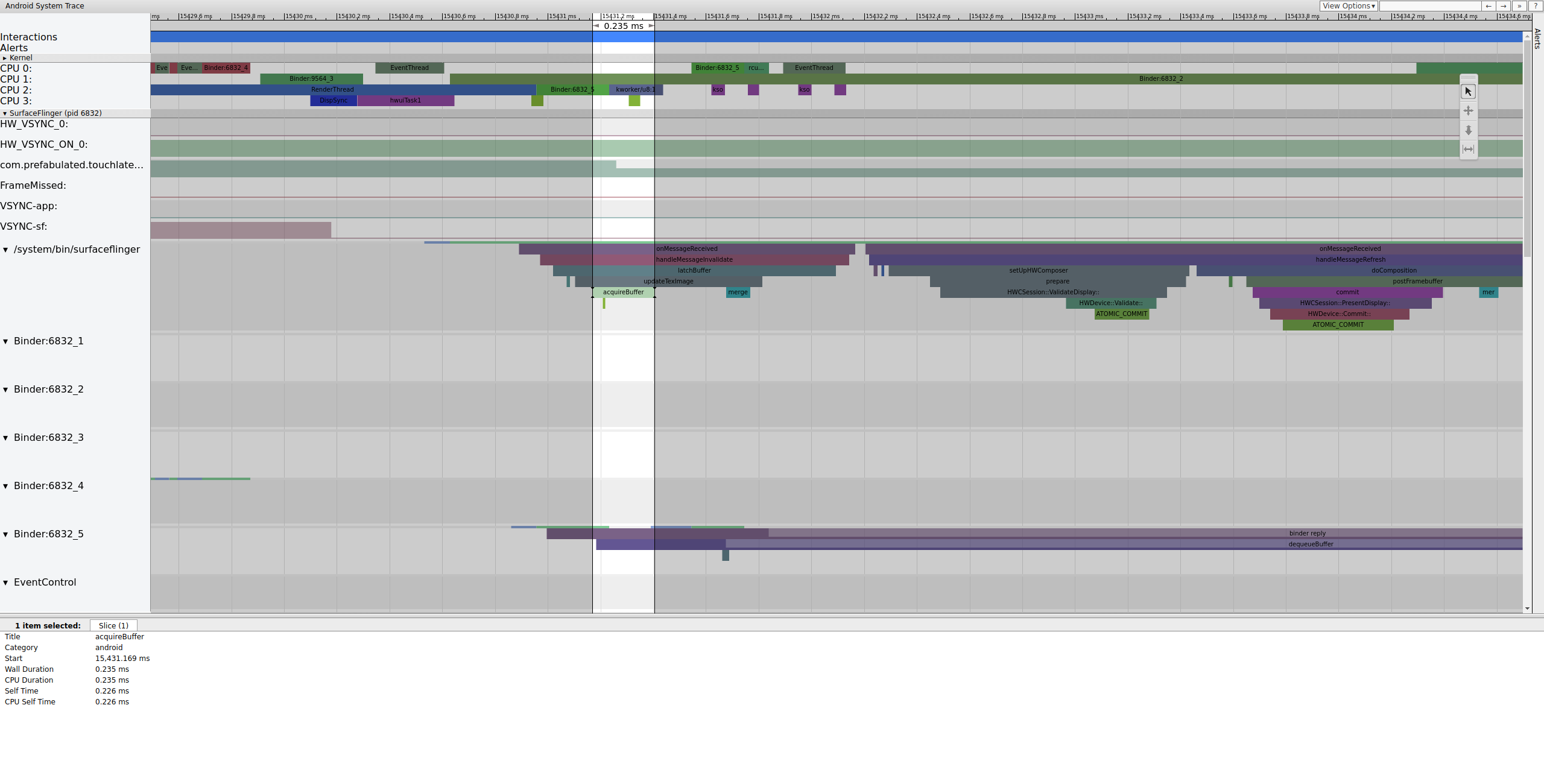
锁定缓冲区后,SurfaceFlinger 设置合成并将最终帧提交到显示屏。(这些部分中的一些已作为 mdss 跟踪点的一部分启用,因此它们可能不包含在您的 SoC 上。)
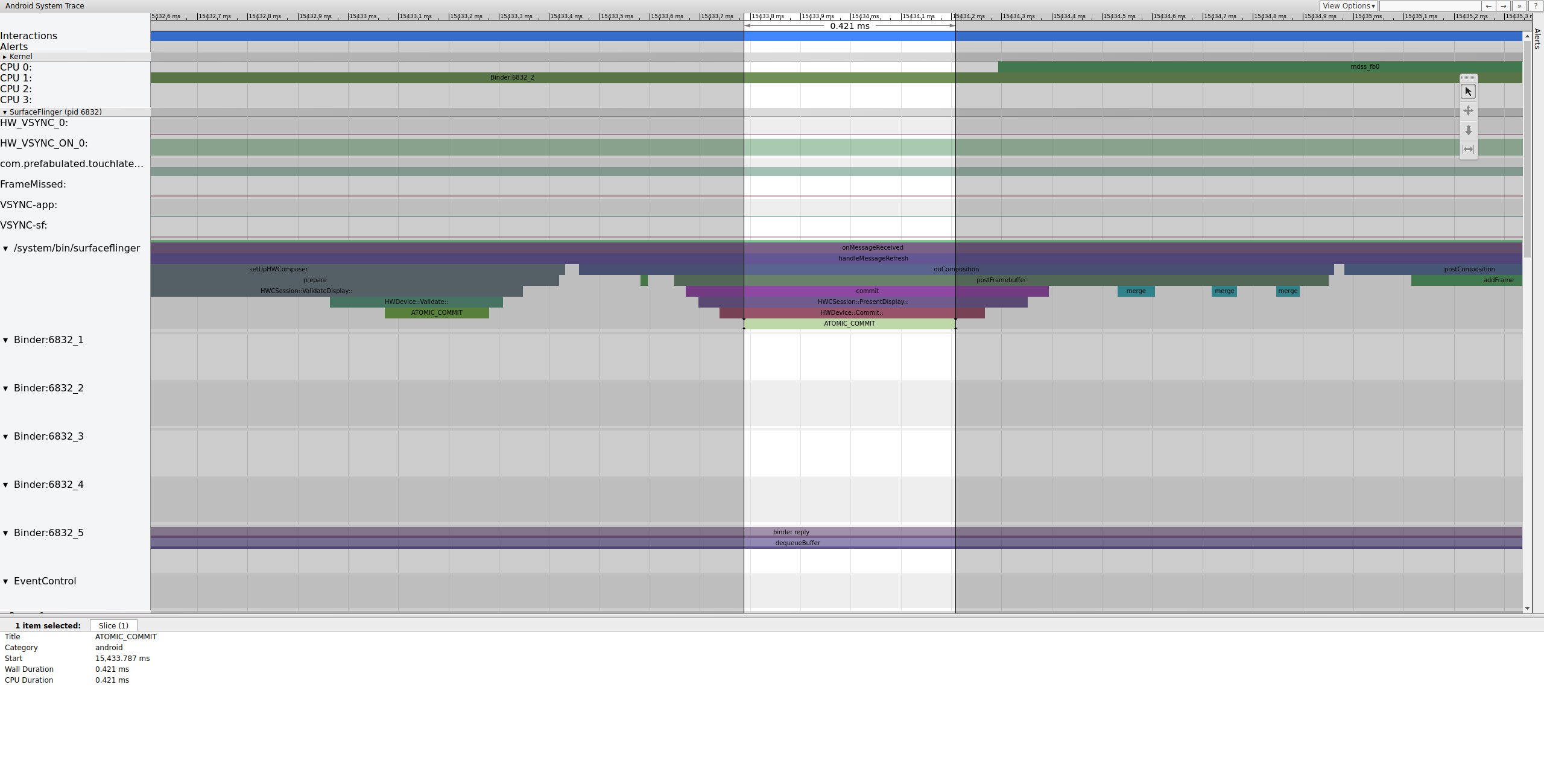
接下来,mdss_fb0 在 CPU 0 上唤醒。mdss_fb0 是显示流水线的内核线程,用于将渲染的帧输出到显示屏。我们可以在跟踪中看到 mdss_fb0 作为其自己的行(向下滚动以查看)。
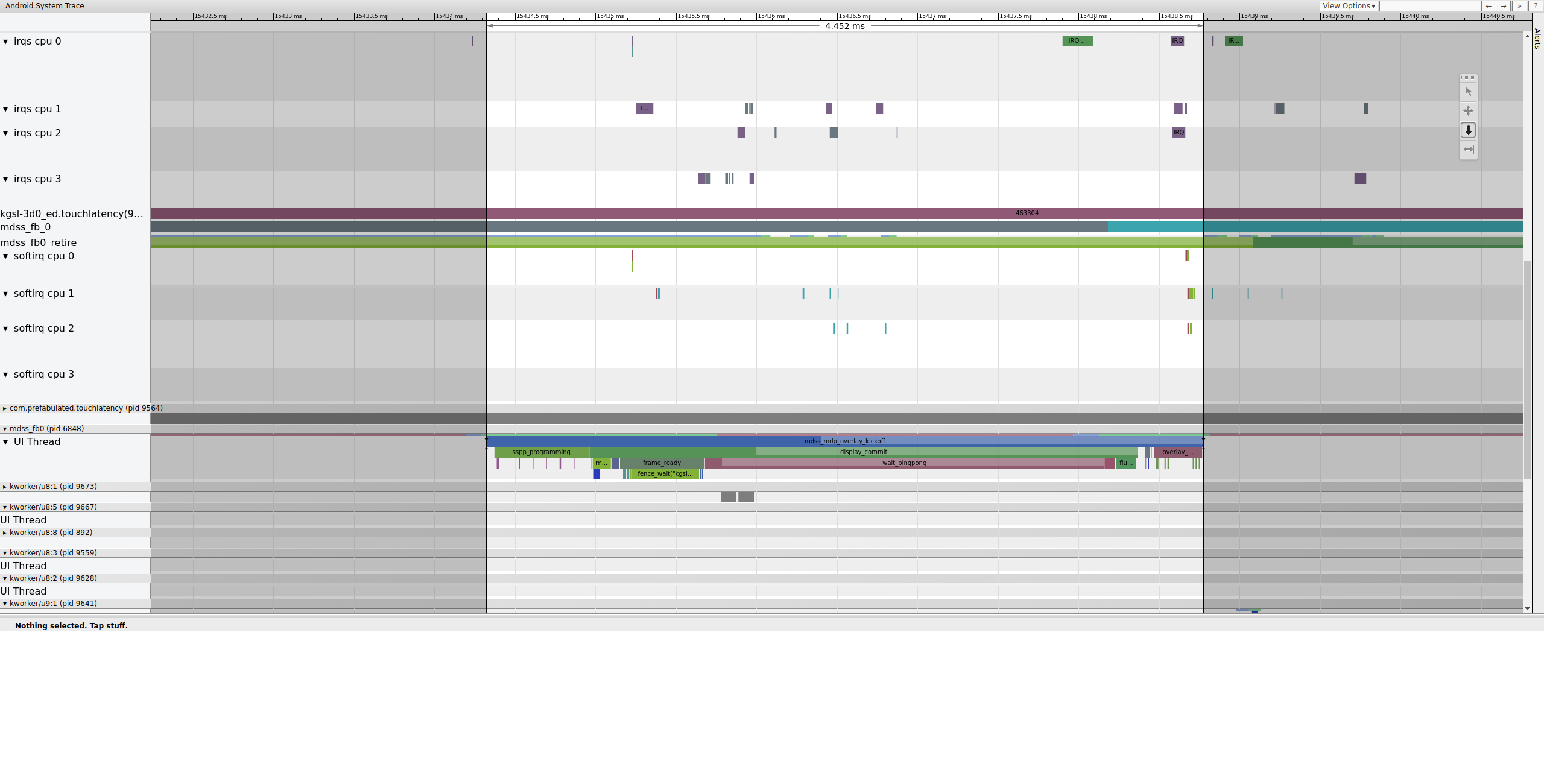
mdss_fb0 唤醒,短暂运行,进入不可中断睡眠,然后再次唤醒。
示例:无法工作的帧
此示例描述了用于调试 Pixel/Pixel XL 抖动的 systrace。要跟随示例进行操作,请下载 zip 文件(其中包含本节中提到的其他跟踪),解压缩文件,然后在浏览器中打开 systrace_tutorial.html 文件。
当您打开 systrace 时,您将看到类似这样的内容

在查找卡顿时,请检查 SurfaceFlinger 下的 FrameMissed 行。FrameMissed 是 HWC2 提供的一种质量改进。当查看其他设备的 systrace 时,如果设备未使用 HWC2,则 FrameMissed 行可能不存在。在任何一种情况下,FrameMissed 都与 SurfaceFlinger 错过其极其规律的运行时之一以及应用 (com.prefabulated.touchlatency) 在 vsync 时的未更改待处理缓冲区计数相关。

图 11 显示在 15598.29&nbps;ms 时错过了帧。SurfaceFlinger 在 vsync 间隔短暂唤醒,然后返回睡眠状态,而没有做任何工作,这意味着 SurfaceFlinger 确定不值得再次尝试向显示屏发送帧。为什么?
要了解此帧的流水线如何崩溃,请首先查看上面的正常工作的帧示例,以了解正常的 UI 流水线在 systrace 中是如何显示的。准备就绪后,返回到错过的帧并向后工作。请注意,SurfaceFlinger 唤醒后立即进入睡眠状态。当查看来自 TouchLatency 的待处理帧数时,有两个帧(有助于弄清楚发生了什么的好线索)。
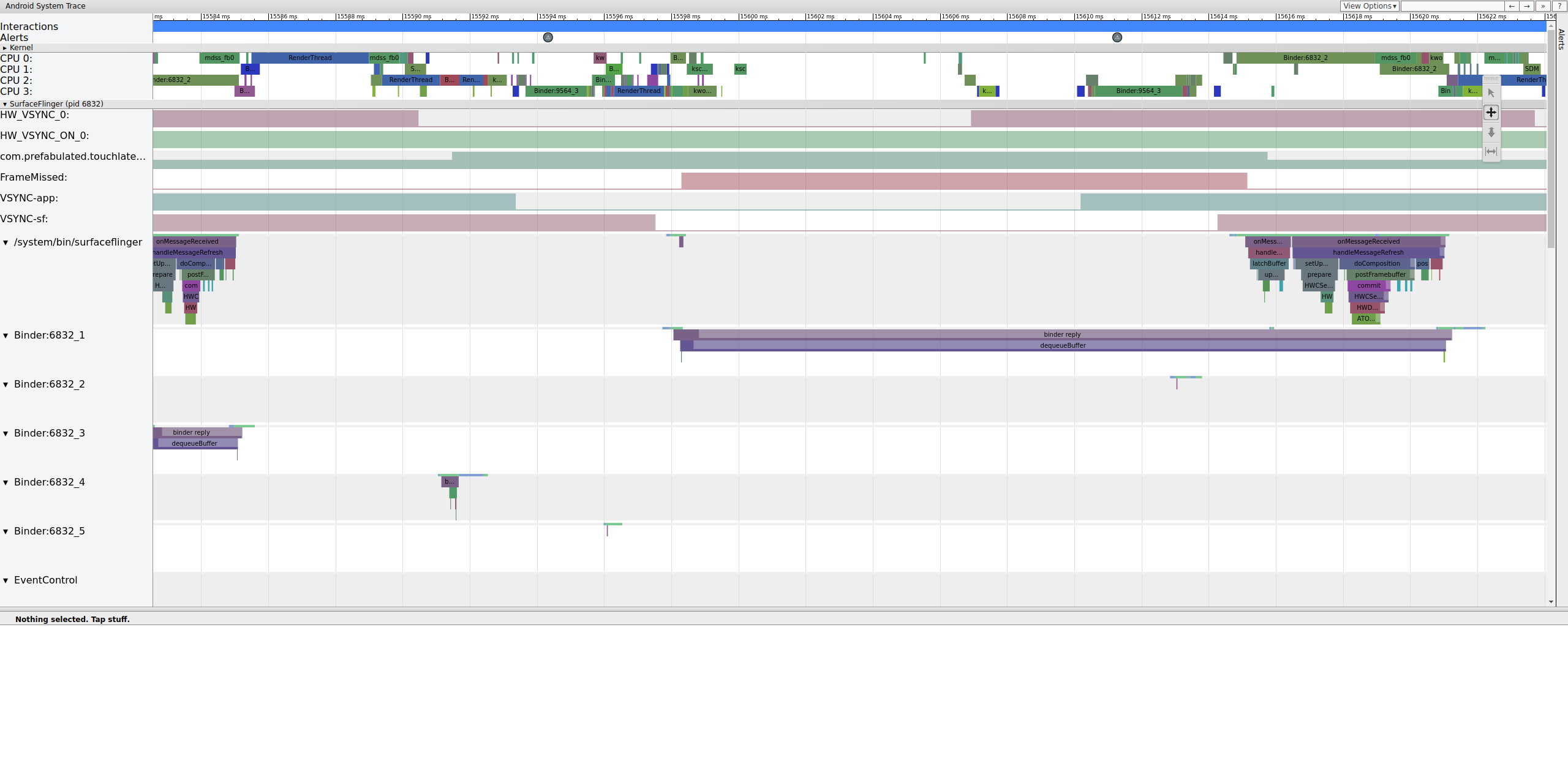
由于我们在 SurfaceFlinger 中有帧,因此这不是应用问题。此外,SurfaceFlinger 在正确的时间唤醒,因此这不是 SurfaceFlinger 问题。如果 SurfaceFlinger 和应用看起来都正常,则可能是驱动程序问题。
由于启用了 mdss 和 sync 跟踪点,我们可以获得有关 fences(在显示驱动程序和 SurfaceFlinger 之间共享)的信息,这些 fences 控制何时将帧提交到显示屏。这些 fences 列在 mdss_fb0_retire 下,表示帧何时在显示屏上。这些 fences 作为 sync 跟踪类别的一部分提供。哪些 fences 对应于 SurfaceFlinger 中的特定事件取决于您的 SOC 和驱动程序堆栈,因此请与您的 SOC 供应商合作以了解您的跟踪中 fence 类别的含义。
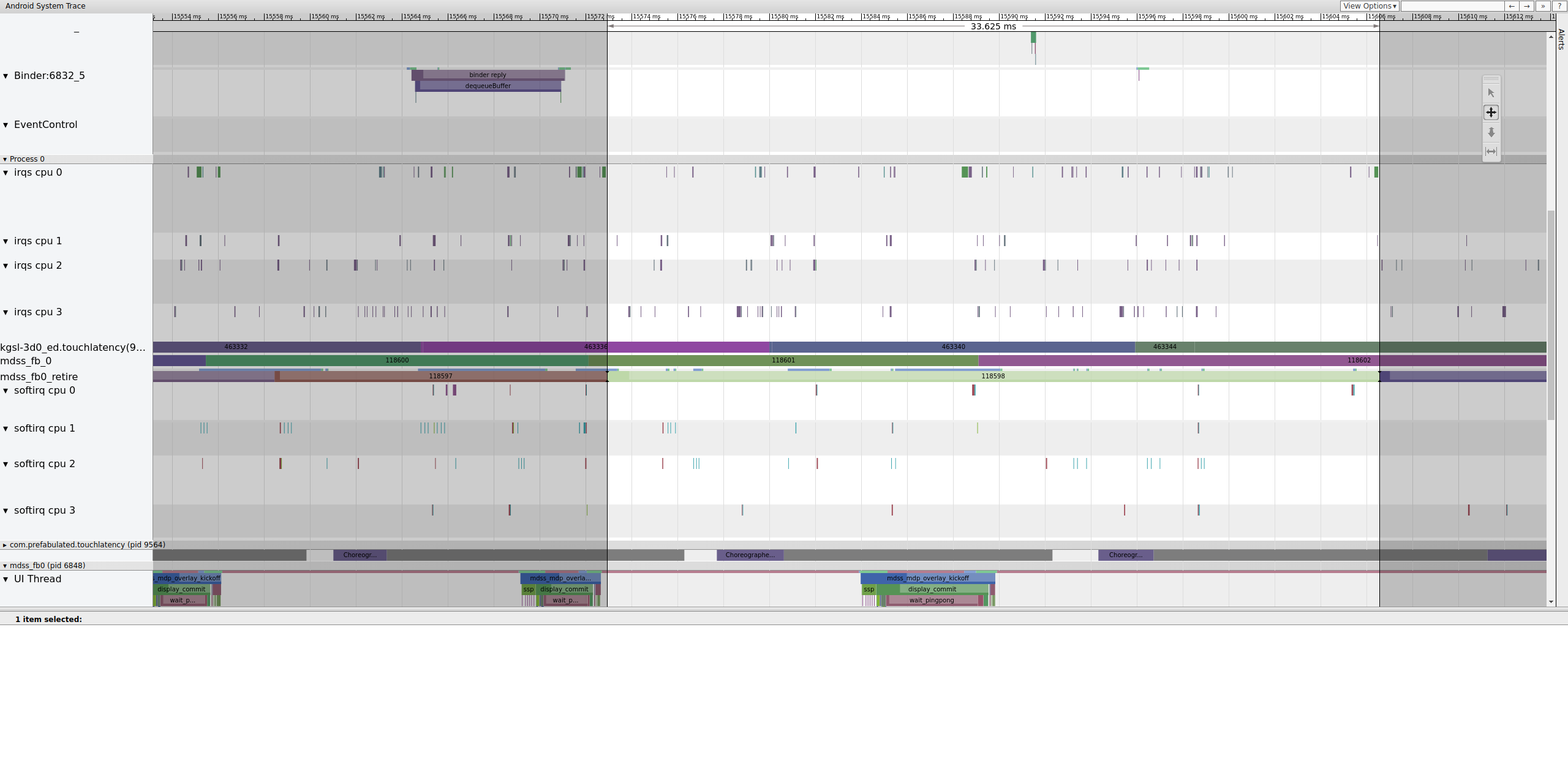
图 13 显示一个帧显示了 33 毫秒,而不是预期的 16.7 毫秒。在该切片的中途,该帧应该已被新帧替换,但没有。查看上一帧并查找任何内容。
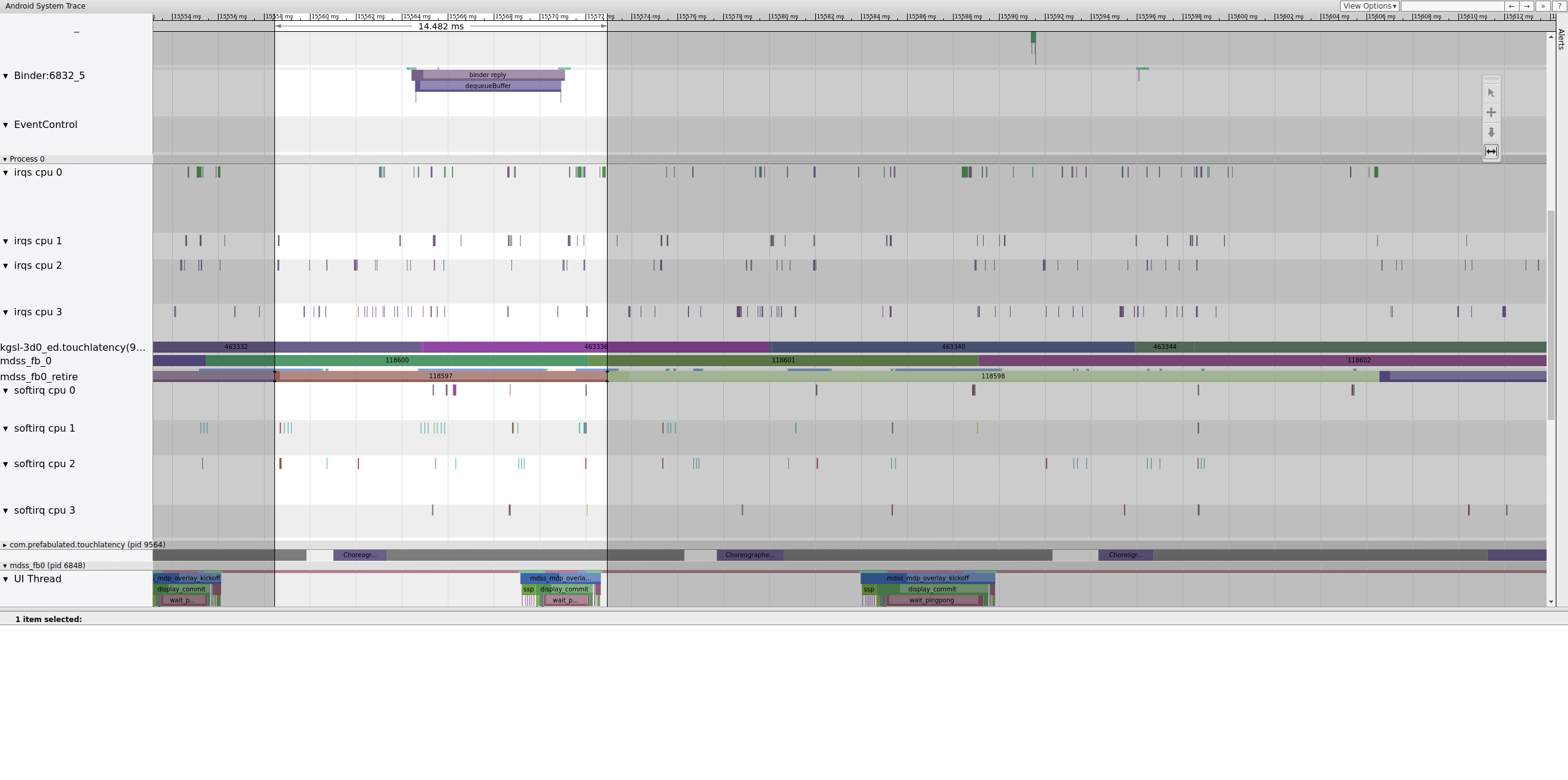
图 14 显示了 14.482 毫秒的帧。破碎的两帧段为 33.6 毫秒,这与我们对两个帧的预期大致相同(我们以 60 Hz 渲染,每帧 16.7 毫秒,这很接近)。但 14.482 毫秒根本不接近 16.7 毫秒,这表明显示管道存在严重问题。
调查该 fence 结束的确切位置,以确定是什么控制它。
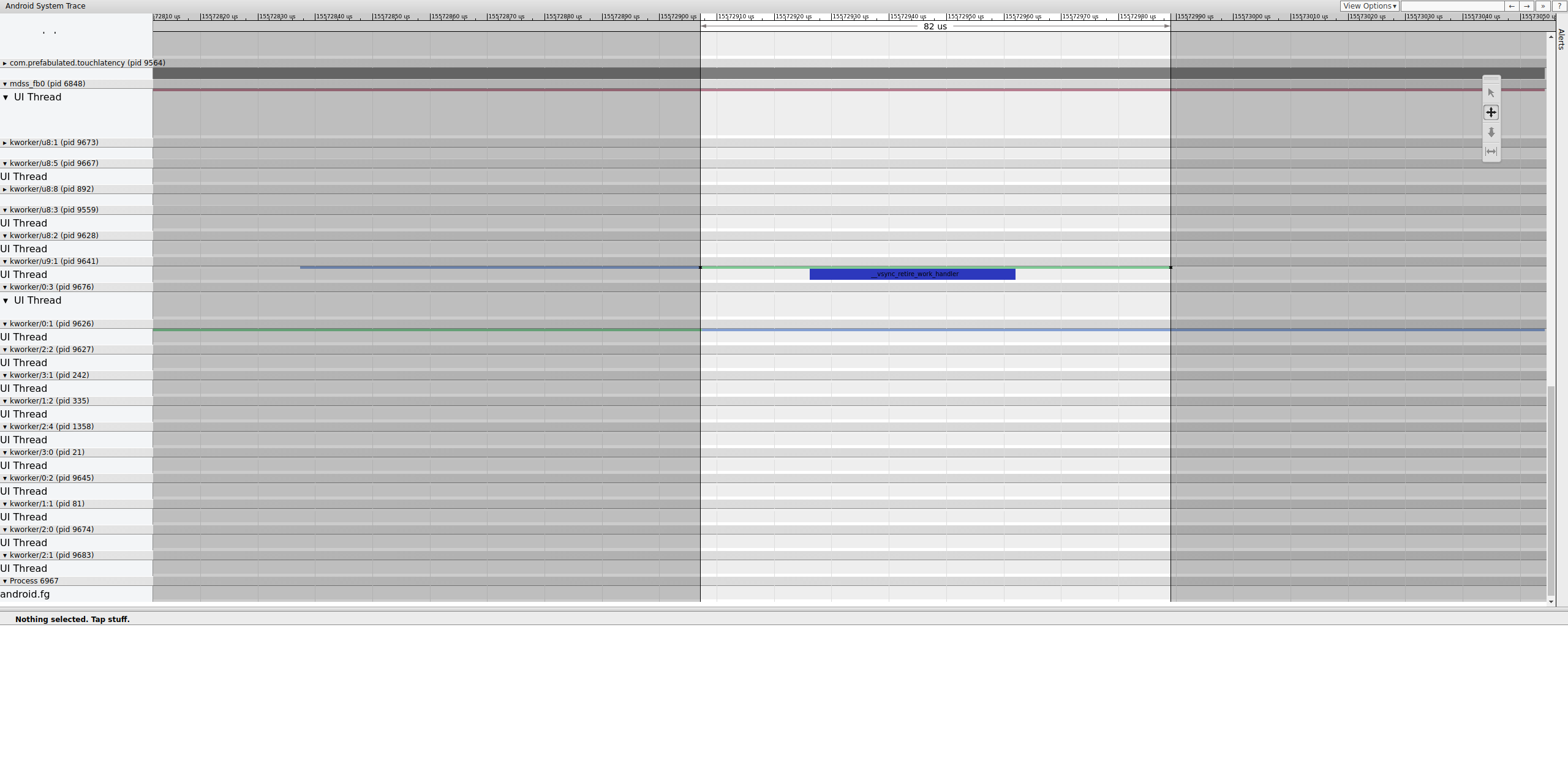
一个 workqueue 包含 __vsync_retire_work_handler,它在 fence 更改时运行。查看内核源代码,您可以看到它是显示驱动程序的一部分。它似乎在显示流水线的关键路径上,因此它必须尽快运行。它可运行约 70 微秒(不是很长的调度延迟),但它是一个 workqueue,可能无法准确调度。
检查上一帧以确定这是否有所贡献;有时抖动会随着时间的推移而累积,最终导致错过截止日期。
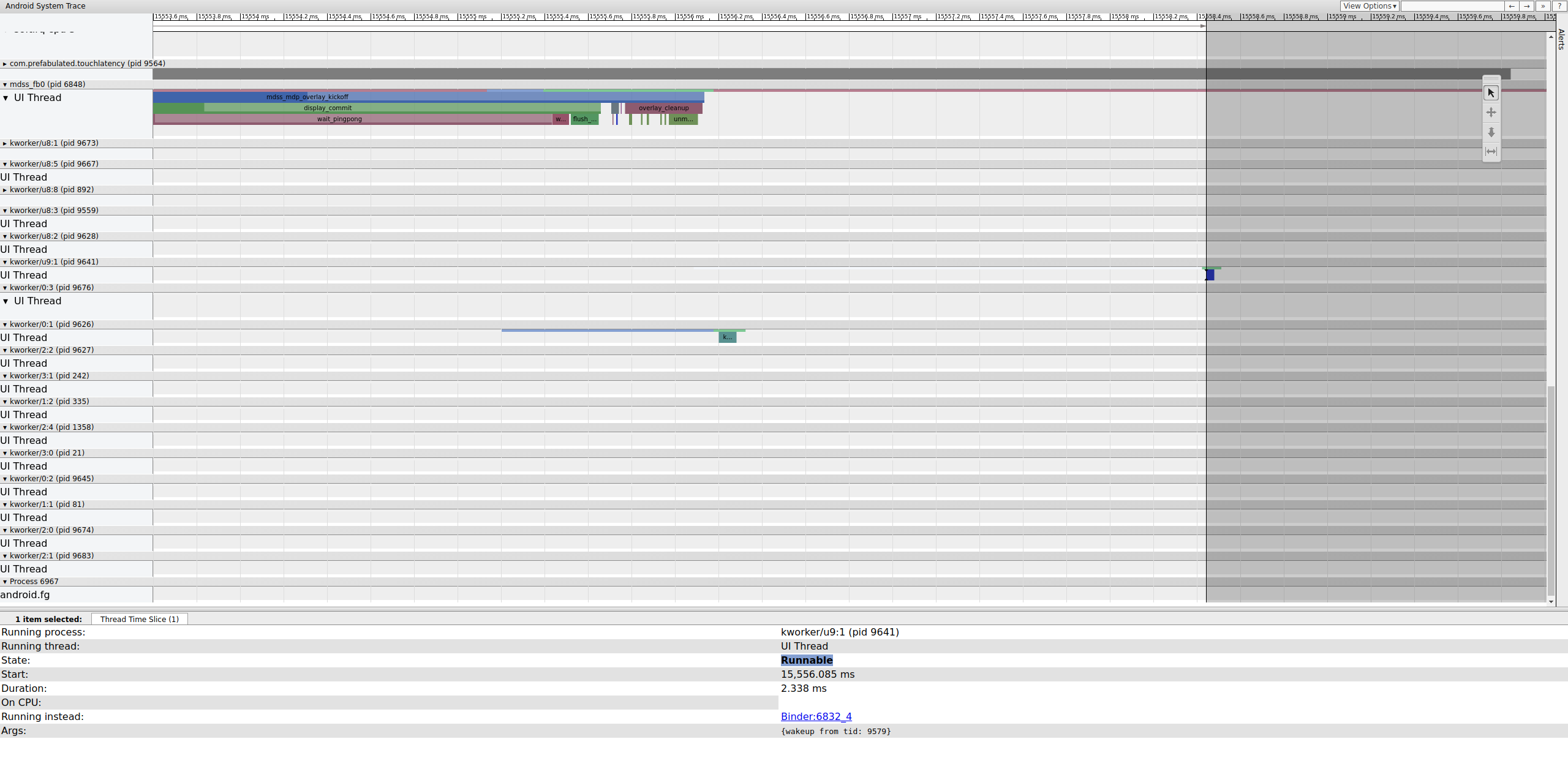
kworker 上的可运行行不可见,因为当选择它时查看器将其变为白色,但统计信息说明了问题:显示流水线关键路径的一部分的 2.3 毫秒调度程序延迟是糟糕的。在继续之前,通过将显示流水线关键路径的这一部分从 workqueue(作为 SCHED_OTHER CFS 线程运行)移动到专用的 SCHED_FIFO kthread 来修复延迟。此功能需要 workqueue 无法(也不打算)提供的定时保证。
这是卡顿的原因吗?很难断定。除了容易诊断的情况(例如内核锁争用导致显示关键线程睡眠)之外,跟踪通常不会指定问题。这种抖动可能是丢帧的原因吗?绝对是。fence 时间应为 16.7 毫秒,但在导致丢帧的帧中,它们根本不接近该值。鉴于显示流水线的紧密耦合程度,fence 时序周围的抖动很可能导致丢帧。
在本示例中,解决方案涉及将 __vsync_retire_work_handler 从 workqueue 转换为专用 kthread。这导致明显的抖动改进并减少了弹跳球测试中的卡顿。后续跟踪显示 fence 时序非常接近 16.7 毫秒。